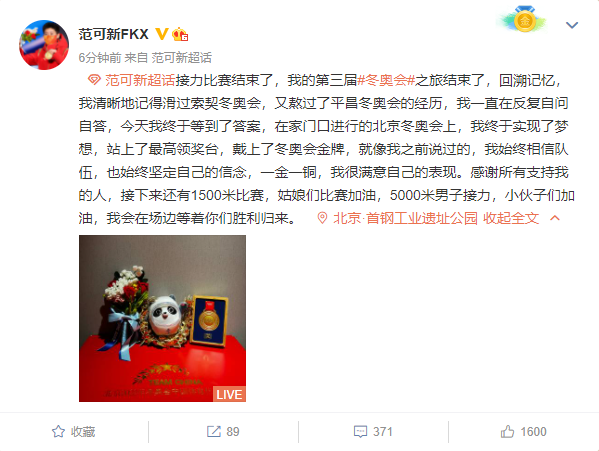
OpenAI现允许网站阻止其爬虫抓取数据
OpenAI旗下GPT模型的训练需要大量的网络数据,这可能涉及到数据隐私和
2023-08-08
 (资料图片仅供参考)
(资料图片仅供参考)
OpenAI 旗下 GPT 模型的训练需要大量的网络数据,这可能涉及到数据隐私和版权等问题。为了解决这些问题,OpenAI 最近推出了一个新功能,让网站可以阻止其网络爬虫(web crawler)从其网站上抓取数据训练 GPT 模型。
网站运营者可以通过在其网站的 Robots.txt 文件中禁止 GPTBot 的访问,或者通过屏蔽其 IP 地址,来阻止 GPTBot 从其网站上抓取数据。
关键词:
[ 相关文章 ]
OpenAI旗下GPT模型的训练需要大量的网络数据,这可能涉及到数据隐私和
在《原神》,随着玩家推进完了蒙德城的故事,打败了风魔龙后,我们玩家
一、湖南省衡阳市天气预报1、衡阳县气象台2023年8月8日8时15分发布高温
中信建投指出,7月市场销售持续承压,重点城市单月新房成交1137 9万方
大S汪小菲官司开打,大S未出庭让律师请假,超10个月未公开露面,大s,小s
为持续推进胸痛、卒中、心律失常三大救治单元建设,完善科学、规范、高
8月7日区块链板块较上一交易日下跌0 07%,创业慧康领跌。当日上证指数
北京时间8月7日,据《世界体育报》报道,前马竞前锋小西蒙尼在租借至阿
8月7日(周一),A股普跌,医药股跌幅最大。截至收盘,上证综指跌0 59%
中科云网(002306):控股子公司中科高邮与湖北三江航天建筑签订了《机电
在一些看得到的地方,华为的“果味”越来越浓了。鸿蒙4给我的感受主要
参考消息网8月7日报道美国《华尔街日报》网站8月5日刊登题为《有中国出
鲁泰A:关于回购公司境内上市外资股(B股)的进展公告
当地时间8月6日,阿富汗国家环境保护局副局长阿比德在新闻发布会上表示
8月10日至12日普洱市镇沅县恩乐镇将举行为期3天的火把节系列活动火把狂
中新网济南8月7日电题:山东盘活闲置宅基地“沉睡老宅”变身“活力股”
进火凝神志不分,阳动药生神凝丹。采药外息即出入,出入升降须包裹
成都大运会开赛以来,赛场内外留下许多精彩瞬间,深受各方关注与好评。
iQOONeo8Pro原装电池能用四年吗,很多都有疑问,以下是相关解答。iQOON
记者今天从北京南站获悉,受山东省德州市平原县发生5 5级地震影响,8月
[ 相关新闻 ]